Previously in ICTO Newsletter, we introduced what data classification is and why you need it. In this issue, we would like to share with you how one can classify the data into different categories.
How to Determine the Data Classification Level?
If you are a data owner, it is your responsibility to identify and classify your data to reflect the degree of protection it requires. When classifying data, you should always consider the sensitivity, risk, and impact if inadvertently data is exposed. You may start by asking following questions.
- Is it intended for public disclosure?
- Does it contain personal data[1], such as ID card number and phone number?
- Does it contain sensitive data[2], suspicion of illegal activities, criminal and administrative offences[3], sick leave certificate and certificate of no criminal conviction, etc.?
- Does the disclosure of data causes any negative impact or significant damage to UM’s reputation? Potential regulatory and/or legal action against the University? Negative financial impact?
[1] The personal data defined in Item 1 of Article 4 of Personal Data Protection Act (Act 8/2005) of Macao
[2] The data defined in Item 1 of Article 7 of Personal Data Protection Act (Act 8/2005) of Macao
[3] The data defined in Item 1 of Article 8 of Personal Data Protection Act (Act 8/2005) of Macao
Following flow chart shows an example of determining the classification level.
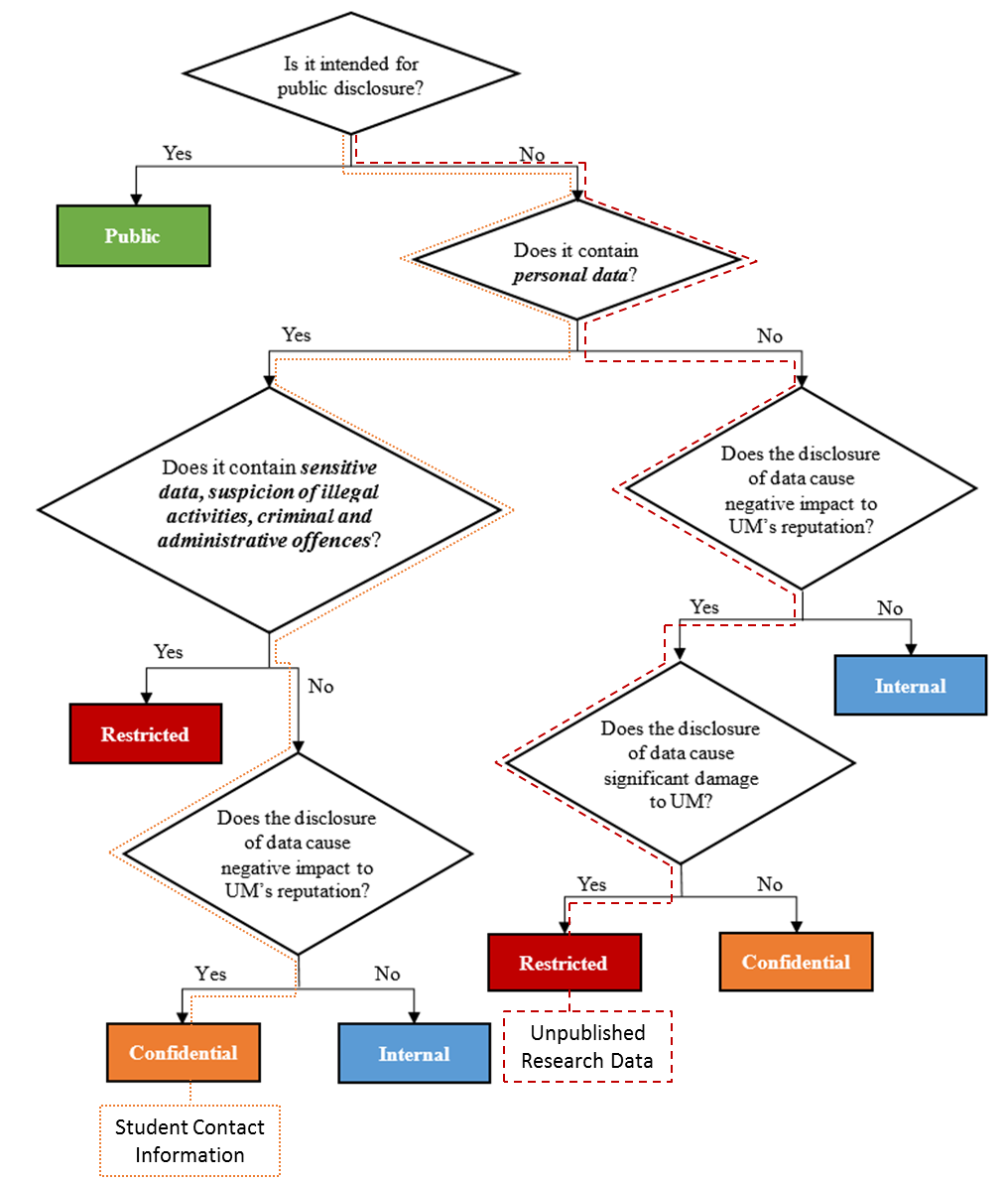
Let’s take unpublished research data and student personal information as example data sets to be classified.
- Unpublished research data: Research data may not contain any personal data but the inadvertent disclosure of data results in significant loss of UM’s academic credibility. As a result credibility issue will make UM much less attractive to top scholars from around the world and will decrease UM’s research capabilities. Therefore, such data should be classified as “Restricted”.
- Student contact information: Contact information is personal data defined in Personal Data Protection Act (Act 8/2005) of Macao. Any misuse or unauthorized disclosure results in legal penalties. Such kind of data should be classified as “Confidential” as it doesn’t contain sensitive data, suspicion of illegal activities, criminal and administrative offences.
When a data set comprises content of different classification levels, the classification with the highest level should be applied to the whole set. For example, if a data set contains both “Confidential” and “Internal” data, the data set should be classified as “Confidential”.
How to Make Sure the Data Classification is Up-to-date?
The law, university regulations, business requirements, organizational structure and responsible parties are changing from time to time, you should review the assigned levels of data classification regularly and reclassify it if necessary.
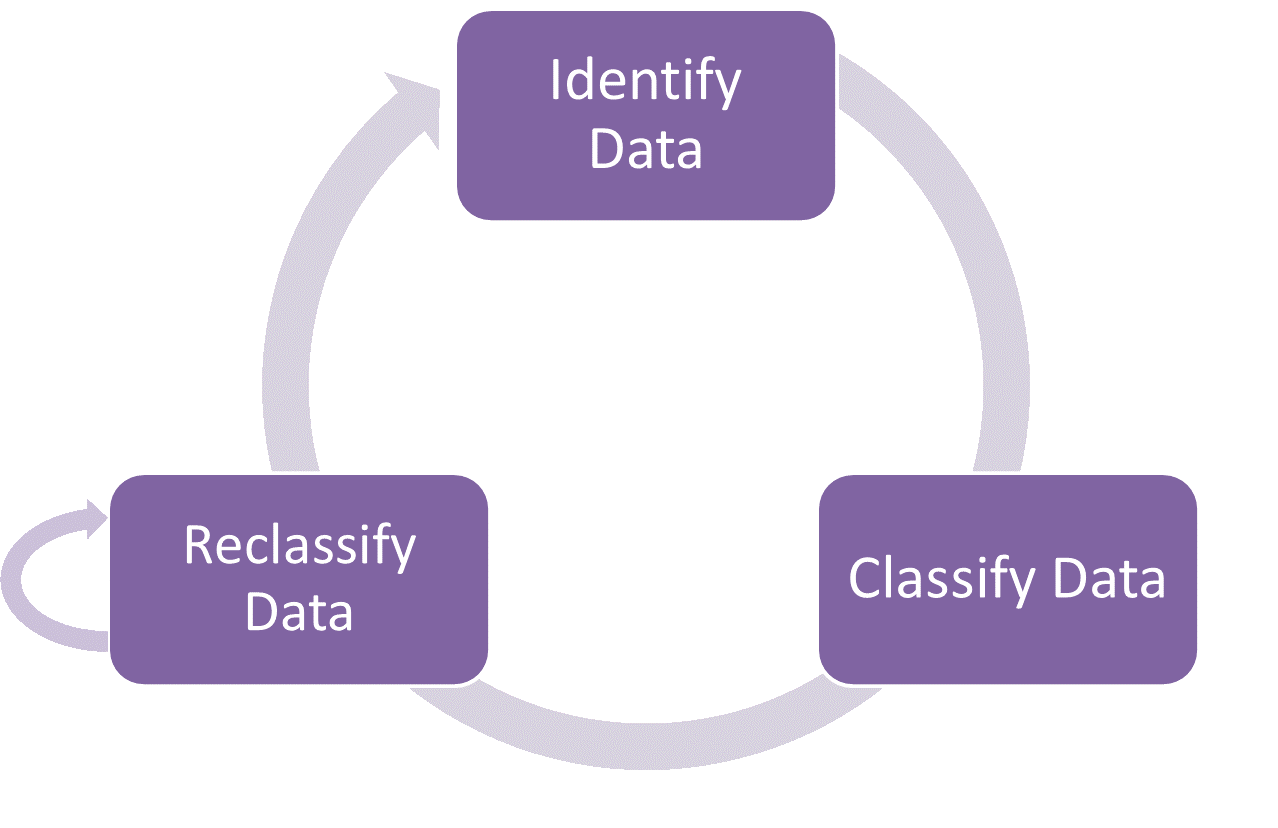
How Does Data Classification Enable Efficient Data Protection?
Security standards that specify appropriate handling practices for each level of data classifications are defined and listed in the following table. Once your data is classified, place proper security measures and controls in place to protect your data. For example, data classified as “Restricted” must be stored in a protected storage and you must get authorization from data owner to access such data. Also, non-disclosure agreement (NDA) must be signed by service providers and other third-parties if they will handle UM data that is classified as “Restricted”, “Confidential” or “Internal”.
As mentioned in the previous article, you should also follow Guidelines for Handling Confidential Information when you are handling Restricted or Confidential information.
Information security is everyone’s responsibility, let’s work together to protect UM’s data.




